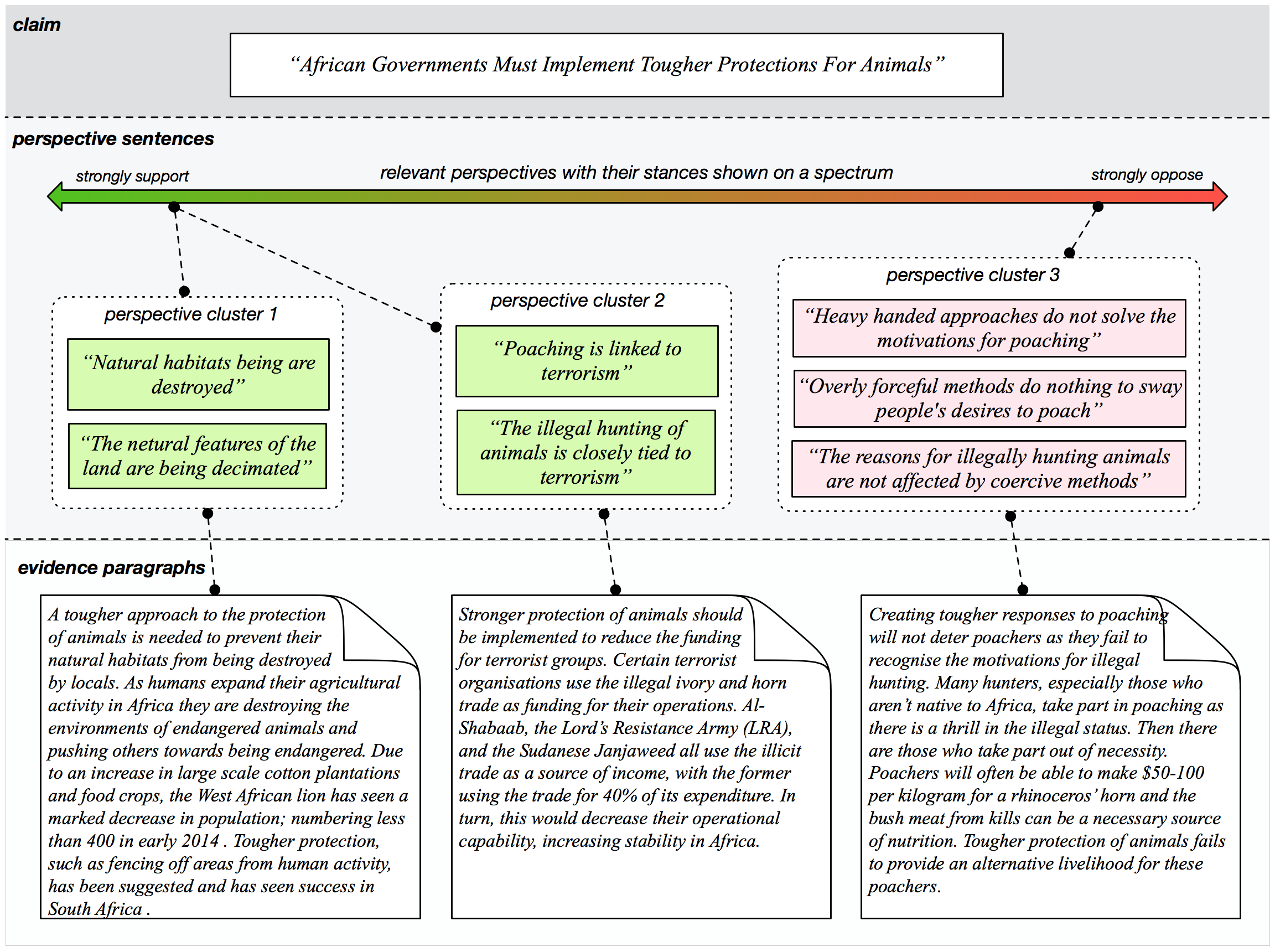
Perspectrum
A dataset of claims, perspectives and evidences
A dataset of claims, perspectives and evidences
@inproceedings{chen2018perspectives, title={Seeing Things from a Different Angle: Discovering Diverse Perspectives about Claims}, author={Chen, Sihao and Khashabi, Daniel and Yin, Wenpeng and Callison-Burch, Chris and Roth, Dan}, book={NAACL}, year={2019} }