Absolute discarding discards features in a target node's weight vector
with weight less than some threshold (specified as a fraction of the default
weight). For example, specifying -d abs:0.1 on the command line means
that when the feature's weight drops below ![]() of the initial weight, the
feature is discarded.
of the initial weight, the
feature is discarded.
Relative discarding compares feature weights across the whole network. The feature with the smallest weight is discarded, and its weight is subtracted from the weight of every other feature in the network. This method was developed specifically for Winnow networks and is probably best used only with Winnow networks.
This parameter is not available in -interactive mode. The default is none.
We note that although the default method is count, if you are interested in generating small hypotheses we are recommending using the relative method which we call percent here. See [Carlson et al., 2001] for experimental evidence.
Using the count method, an integer threshold is specified, and features become eligible as soon as their active counts become equal to that threshold. Before then, they are pending (not eligible, but not discarded either). See the -s parameter for a description of what makes a feature's active count within a given target node go up. Experiments with a small number of examples may benefit from setting this parameter to count:1.
For example, if -e count:3 is specified and feature ![]() appears
twice in the training file, then this feature would never be included in
activation calculations during training, and it would not be written to the
network file after training is complete (see the -a parameter for the
only exception to this rule).
appears
twice in the training file, then this feature would never be included in
activation calculations during training, and it would not be written to the
network file after training is complete (see the -a parameter for the
only exception to this rule).
Using the percent method, the specified floating point threshold represents a fraction of total feature occurrences. During first cycle of training, all features are considered eligible. After the first cycle, a histogram of feature frequencies (active counts) is created for each target node. Starting with the highest frequencies, features are declared eligible until the total number of eligible feature occurrences within a given target node meets the specified percentage. All other features become pending. Again, see the -s parameter for a description of what makes a feature's active count within a given target node go up.
For example, let ![]() be the number of features observed with a specific target
node
be the number of features observed with a specific target
node ![]() (one of which is feature
(one of which is feature ![]() ), and let
), and let
![]() ,
, ![]() ,
be the features that are active more times than feature
,
be the features that are active more times than feature ![]() in examples in
which
in examples in
which ![]() is also active. Also, let
is also active. Also, let ![]() be the number of times feature
be the number of times feature
![]() is active with
is active with ![]() , and let
, and let ![]() represent the user specified
percentage eligibility (as in -e percent:
represent the user specified
percentage eligibility (as in -e percent:![]() ). Then, if the
condition
). Then, if the
condition
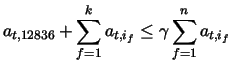
holds true, then feature ![]() will remain eligible for participation in
updates and activation calculations (as will all features
will remain eligible for participation in
updates and activation calculations (as will all features
![]() ).
Otherwise, feature
).
Otherwise, feature ![]() will become pending.
will become pending.
The -e parameter also affects -test mode. When the network is read in, each feature's eligibility (either ``eligible'' or ``pending'') is assigned according this parameter's setting and the active count found for the feature in the network file. This parameter is not available in -interactive mode. The default setting of this parameter in both training and testing is count:2.
The fixed feature acts as a dynamic threshold in Winnow and Perceptron learners. The total activation produced by each example (including the fixed feature) is still compared to the constant threshold specified on the command line to determine if a mistake has been made (unless -O + has also been specified), but with the fixed feature enabled, this threshold can be thought of as merely the constant component of a dynamic threshold. This parameter is available in every execution mode. Default +.
If -g - is specified, no conjunctions will be generated. If neither is specified, SNoW will examine the training data to decide if conjunctions would be useful. SNoW decides to generate conjunctions automatically if fewer than 100 unique features are present in the training data.
Users also have the option of writing the new examples to disk by specifying an additional argument. If -g +,+ is specified, input examples will be written to disk with conjunctions added. They will be output into a file whose name is the original filename concatenated with ``.conjunctions''. If no conjunctions are generated, the file will be left empty.
The setting of the first argument to this parameter is written to the network, but the second argument is not. This parameter is not available in -interactive mode. The default is -g <unset>,-, when SNoW will examine the training data to decide if conjunctions should be generated and no examples are written to disk.
If -m - is specified, a given target will treat other targets as features, and will therefore use those other target's strengths in the example for activation calculations in training. In testing, the example is only counted as correct if the predicted target is the first target found in the example.
This parameter can be set in every execution mode, but will not make any difference in any mode unless there exist examples with more than one target active. This parameter is not available in -interactive mode. Default +.
In either kind of network, active counts are only incremented during the first cycle of -train mode and when -i + is specified in -test mode. This is important for eligibility (see -e), the rules of which are applicable whether the network is full or sparse. This parameter is not available in -interactive mode. Default s.
-e count:1 -f - -g - -r 1 -s f
If any of these parameters are specified in addition to -z + on the command line, the extra command line settings will override those that -z + imposes no matter where in the command line they occur. This parameter is not available in -evaluate or -server mode. This parameter is not available in -interactive mode. Default -.