Next: Training Parameters
Up: Command Line Parameters
Previous: Command Line Parameters
Contents
SNoW is prepared with a useful default architecture that performs well in many
situations. Many alternative architectures can also be specified either
directly in the command line or using an architecture file as described below.
The main component of an architecture definition is the target node
description. Each target node can be trained using a different update rule
(learning algorithm) although it's more common to use the same update rule for
all targets. For each target, at least one update rule used to learn its
representation must be specified. If Winnow (-W) or Perceptron (-P) are used, it is also possible to specify their parameters; otherwise,
default parameters are used. Target nodes are declared by listing those nodes
which will be associated with each algorithm. Either single IDs or ranges of
targets can be given.
For example, this is probably the simplest architecture that can be specified:
-W :0-1
It declares two target nodes, for the target IDs 0 and 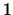 , to be learned
using the Winnow update rule with default parameters. This architecture is
suitable for a two-class learning scenario.
, to be learned
using the Winnow update rule with default parameters. This architecture is
suitable for a two-class learning scenario.
Here's an example of a more complicated architecture:
-W 1.5,0.8,4.0,0.5:0-2,5,9
-P 0.1,4.0,0.2:1-3,4,8
Here, Winnow will be used to learn a representation for targets 0, 1, 2, 5,
and 9, and Perceptron will be used for targets 1, 2, 3, 4, and 8. Note that
when more than one algorithm is specified for a single target ID, the outputs
of those algorithms will be combined into a single prediction confidence for
that target (see Section 4.3.5). In the above case, all target
nodes trained with Winnow will be trained with the same parameters, and all
those trained with Perceptron will be trained with the same parameters. Note
that one can also train different target nodes with different parameter
settings of the same algorithm.
Command line parameters for designing architectures with SNoW's various
supported algorithms either on the command line or in architecture files are
described below.
- -A <architecture file>
- : Specifies the name of a file from which to read the desired architecture
definition and parameters. The file may look, for example, like:
-W 1.5,0.8,4.0,0.5:0-1
-P 0.1,4.0,0.20:0-1
-e count:1
-r 4
This parameter has no default.
- -B -P -W
- : These three parameters instantiate naive Bayes, Perceptron, and Winnow
learners respectively. If none of them are specified, a default Winnow
architecture is instantiated. They are -train mode parameters that have
no effect in any other mode.
Table 5.1:
Default algorithmic parameters for SNoW's algorithms. Perceptron
uses its ``learning rate'' for promotion, and the opposite thereof for
demotion. Winnow uses 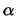 for promotion and
for promotion and 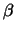 for demotion.
for demotion.
| Algorithmic parameter |
Perceptron |
Winnow |
| (learning rate) |
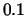 |
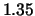 |
|
- |
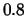 |
| threshold |
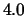 |
|
| initial feature weight |
See Section 4.2 |
|
They also must each be followed by arguments, which are described in detail
below. The arguments that follow each of these parameters may not have any
whitespace between them; they are instead separated by commas and colons. Any
<targets> argument may make use of commas and hyphens to specify ranges
of target IDs. When using -interactive mode, none of the arguments to
-P or -W may be omitted. Otherwise, some of them can be omitted,
and when they are, they take the defaults listed in table 5.1.
See below for more details.
- -B :<targets>
- : Specifies the targets to train with naive Bayes.
Targets must always be specified. This parameter is not available in -interactive mode.
- -P <learning_rate>,<threshold>,<initial_weight>:<targets>
- :
Specifies the targets to train with the single layer Perceptron algorithm,
along with explicit algorithm parameters. Here all parameters are stated
explicitly.
- -P <learning_rate>,<threshold>:<targets>
- : Specifies the targets
to train with the single layer Perceptron algorithm, along with explicit
algorithm parameters. Here, the initial weight is omitted, and is thus
calculated as a function of the threshold and the average number of active
features per example5.1.
- -P <learning_rate>:<targets>
- : Specifies the targets to train
with the single layer Perceptron algorithm, along with the
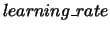 .
Here a default threshold is used, and the initial weight is calculated as a
function of the threshold and the average number of active features per
example.
.
Here a default threshold is used, and the initial weight is calculated as a
function of the threshold and the average number of active features per
example.
- -P :<targets>
- : Specifies the targets to train with the single
layer Perceptron algorithm, and uses default algorithm parameters. Targets
must always be specified.
- -W <promotion>,<demotion>,<threshold>,<initial_weight>:<targets>
- : Specifies which targets to train with the Winnow algorithm along with
explicit algorithm parameters. All parameters are stated explicitly.
- -W <promotion>,<demotion>,<threshold>:<targets>
- : Specifies the
targets to train with the Winnow algorithm along with explicit algorithm
parameters. Here, the initial weight is omitted, and is thus calculated as a
function of the threshold and the average number of active features per
example.
- -W <promotion>,<demotion>:<targets>
- : Specifies the targets to
train with the Winnow algorithm along with explicit algorithm parameters.
Here, a default threshold is used, and the initial weight is calculated as a
function of the threshold and the average number of active features per
example.
- -W :<targets>
- : Specifies the targets to train with the Winnow
algorithm and default algorithm parameters. Targets must always be specified.
- -G <+ | ->
- : Setting this parameter to + enables the function approximation
(regression) algorithm. This algorithm is non-mistake-driven, meaning that
each target node an example is presented to will perform an update on that
example whether the network can be said to have made a mistake on that example
or not. This option can be enabled in conjunction with Perceptron, giving
rise to a stochastic approximation to the Gradient Descent algorithm, or with
Winnow, resulting in an Exponentiated Gradient Descent algorithm. Please see
Section 4.3.3 for details on these algorithms.
Naive Bayes does not have a Gradient Descent update rule. In both Winnow and
Perceptron, each example is presented only to targets active in that example.
Gradient Descent cannot be enabled at the same time as either Constraint
Classification (Section 4.3.1) or threshold relative updating
(Section 4.3.6). If -O + and -G + are specified,
-G is automatically set to -. Otherwise, if -t + and -G + are specified, -t is automatically set to -. This parameter
is not available in -interactive mode. Default -.
- -O <+ | ->
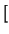 ,<+ | ->
,<+ | ->![$ ]$](img94.gif)
- : This parameter is used to enable the true multi-class (a.k.a. Constraint
Classification or ``Ordered Targets'') training algorithm. When set to -, each target node learns a simple relation between the features and a class
label without any interaction with the other target nodes. Setting this
parameter to + enables the Constraint Classification training algorithm,
in which target nodes compare their activations with each other to determine
which will be promoted or demoted. The optional second argument to this
parameter, which is only recognized when the first argument is set to +,
enables the conservative version of this algorithm when set to +.
Omitting the second argument is the same as setting +,-. See a
discussion of the algorithmic details in Section 4.3.1.
Note that with -O +, the threshold parameter specified on the command
line for Winnow and Perceptron learners is never involved in training unless
-t + is also specified. The setting of this parameter is not stored in
the network file. This parameter is not available in -interactive mode.
Default -,-.
- -S <p>,<n>
- : Specifies the floating point thickness of the separator between positive and
negative examples for training Perceptron and Winnow learners. This option is
the regularization option of SNoW and it is described in detail in
Section 4.3.2. Generally, the goal of this option is to modify
the given algorithm such that it tries to fit a thicker hyperplane between
positive and negative examples. We have found that any setting of this
parameter from -S 1.0 to -S 2.5 most often results in better
performance of the learned network (but, of course, this finding is
intrinsically dataset dependent).
If the ,<n> is not specified, 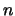 will take the same value as
will take the same value as 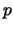 . This
parameter will not have any effect if -O + is also specified. The
setting of this parameter is not stored in the network file. This parameter
is not available in -interactive mode. Default 0,0.
. This
parameter will not have any effect if -O + is also specified. The
setting of this parameter is not stored in the network file. This parameter
is not available in -interactive mode. Default 0,0.
- -t <+ | ->
- : This parameter is for enabling threshold relative updating in either of the
Winnow or Perceptron update rules. Setting it to + enables the
algorithm. In threshold relative updating, the respective learning rate
parameters for each update rule are intended to synchronize the example's
updated activation with the algorithm's threshold setting, save for a small
buffer. A discussion and the algorithmic details of this option are described
in Section 4.3.6.
This parameter has no effect when -G + is also specified. See the
description of -G for more details. This parameter is not available in
-interactive mode. Default -.
Footnotes
- ... example5.1
- See Section 4.2 for more
details
Next: Training Parameters
Up: Command Line Parameters
Previous: Command Line Parameters
Contents
Cognitive Computations
2004-08-20