Each target node in SNoW is learned as a linear function of the features found
active with its target ID in the training set. One way to increase the
expressivity of this representation is to allow each target (class label) to
be represented as a weighted combination of target nodes' output. SNoW
supports this by allowing more than one target node, potentially learned by
different learning algorithms, to represent the same class label. Those that
do are grouped into clouds, in which they collectively provide the
output for a single target. For example, target ![]() could be the combination
of two target nodes, one learned using Perceptron and one learned using
Winnow, while target
could be the combination
of two target nodes, one learned using Perceptron and one learned using
Winnow, while target ![]() is a combination of a naive Bayes learner and a
Winnow learner.
is a combination of a naive Bayes learner and a
Winnow learner.
Each linear function that participates in this combination is trained
individually according to its own parameters. Only at decision time is the
target's prediction confidence determined as a weighted sum of the individual
target nodes' sigmoid activations with coefficients that are a function of the
cumulative number of mistakes made by each target node in the cloud during
training. In light of this, the target ![]() predicted by SNoW's
winner-take-all testing policy for an example
predicted by SNoW's
winner-take-all testing policy for an example ![]() can be stated more generally
than it was in Section 4.1 as:
can be stated more generally
than it was in Section 4.1 as:
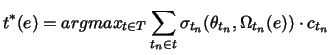
where ![]() is the set of all possible predictions (class labels), each
is the set of all possible predictions (class labels), each ![]() is
a target node,
is
a target node,
![]() is the threshold of the algorithm associated
with
is the threshold of the algorithm associated
with ![]() ,
,
![]() is the activation calculated by
is the activation calculated by ![]() for
for ![]() ,
,
![]() is the algorithm specific sigmoid function
discussed in Sections 4.1 and 4.2, and
is the algorithm specific sigmoid function
discussed in Sections 4.1 and 4.2, and ![]() is
is
![]() 's cloud confidence (discussed next).
's cloud confidence (discussed next).
Cloud confidence is a floating point value stored in each target node
and initialized to ![]() . When
. When ![]() makes a mistake during training, its cloud
confidence
makes a mistake during training, its cloud
confidence ![]() is updated with the following formula:
is updated with the following formula:
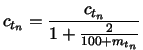
where ![]() is the total number of mistakes made by target node
is the total number of mistakes made by target node ![]() so
far. This formula was designed to decrease cloud confidence at a decreasing
rate so that a cloud confidence value is still representable by a
double-precision floating point variable after many mistakes. Note that the
value that
so
far. This formula was designed to decrease cloud confidence at a decreasing
rate so that a cloud confidence value is still representable by a
double-precision floating point variable after many mistakes. Note that the
value that ![]() is divided by approaches
is divided by approaches ![]() as the number of mistakes
approaches
as the number of mistakes
approaches ![]() . For instance, after the first mistake, the cloud
confidence of
. For instance, after the first mistake, the cloud
confidence of ![]() is roughly
is roughly ![]() . After
. After ![]() mistakes, the cloud
confidence is roughly
mistakes, the cloud
confidence is roughly ![]() , and after
, and after ![]() mistakes, the cloud
confidence is roughly
mistakes, the cloud
confidence is roughly
![]() .
.
Cloud confidence values are only updated in SNoW's -train mode. After SNoW has finished training on all examples, cloud confidences are then normalized so that they sum to 1 within each cloud. When incremental learning is enabled (see the -i option) and SNoW is in -test mode, cloud confidence values are read from the network file and used in example evaluation, but they are not updated.