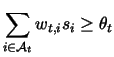The SNoW learning architecture framework is a sparse network of linear units over a Boolean or real valued feature space.
In SNoW's most basic architectural instantiation, a two layer network is maintained. The input layer is the features layer. Nodes in this layer are allocated to features observed in training examples. The second layer consists of target nodes. Each target node corresponds to a concept (a class label) one wants to represent as a function of the input features.4.1 For example, when learning a Boolean function, it is most common to use two target nodes; one representing the positive examples and one the negative. Architectural instantiations can also redefine the number of targets, target nodes, and their types, choice of algorithms and algorithmic parameters, and more.
SNoW expects a set of examples as input. During training, each target node
uses all examples provided to learn a representation of its concept as a
function of (some of) the features. During evaluation/testing, these learned
representations are evaluated on a given example to yield a prediction. An
incremental mode in which training continues along with testing is also
available. SNoW makes use of the infinite attribute domain [Blum, 1992] as
opposed to the standard example representation as an array of Boolean or real
values, one per feature in the feature space, where element ![]() in the array
specifies the strength of feature
in the array
specifies the strength of feature ![]() . As such, examples are
represented as a list of active features. Features that would have a strength
of 0 in the classical definition are not listed. Each example is thus a
list of feature indices (possibly associated with a real valued strength).
This is done in anticipation of a very large feature space and sparse
examples; that is, only a small percentage of all possible features are active
in each example.
. As such, examples are
represented as a list of active features. Features that would have a strength
of 0 in the classical definition are not listed. Each example is thus a
list of feature indices (possibly associated with a real valued strength).
This is done in anticipation of a very large feature space and sparse
examples; that is, only a small percentage of all possible features are active
in each example.
Target nodes are linked via weighted edges to (some of the) input features.
Edges are allocated dynamically; a feature ![]() is allocated and linked to
target node
is allocated and linked to
target node ![]() if and only if
if and only if ![]() is present in an example labeled
is present in an example labeled ![]() . It
is also possible to make more complex decisions about which features to
include in the network4.2. Since such decisions are made throughout the first pass through
the training set, the full benefit of the information in each example may not
be reaped after that first pass. Therefore, SNoW processes the training set
twice by default, and the number of passes or cycles can be modified on
the command line (see the -r command line parameter).
. It
is also possible to make more complex decisions about which features to
include in the network4.2. Since such decisions are made throughout the first pass through
the training set, the full benefit of the information in each example may not
be reaped after that first pass. Therefore, SNoW processes the training set
twice by default, and the number of passes or cycles can be modified on
the command line (see the -r command line parameter).
Let
![]() be the set of features that are
active in an example and are linked to target node
be the set of features that are
active in an example and are linked to target node ![]() . Let
. Let ![]() be the real
valued strength associated with feature
be the real
valued strength associated with feature ![]() (default:
(default: ![]() ) in the example.
Then we say that
) in the example.
Then we say that ![]() predicts positive if and only if
predicts positive if and only if
where ![]() is the weight on the edge connecting the
is the weight on the edge connecting the ![]() feature to
target node
feature to
target node ![]() , and
, and ![]() is
is ![]() 's threshold.
's threshold.
The real-valued result of the summation in equation 4.1 is
also referred to as the target node's activation. Target node
activations drive weight vector updates during training as well as predictions
during testing. The default testing policy for multiple target networks is a
winner-take-all rule. Let ![]() be the set of all targets defined in the
current architecture instantiation. The predicted target
be the set of all targets defined in the
current architecture instantiation. The predicted target ![]() for example
for example
![]() with a set of active features
with a set of active features
![]() is:4.3
is:4.3
where
![]() is the activation calculated by the summation in
equation 4.1 for target node
is the activation calculated by the summation in
equation 4.1 for target node ![]() given
given ![]() , and
, and
![]() is a learning algorithm specific sigmoid
function4.4 whose
transition from an output close to 0 to an output close to
is a learning algorithm specific sigmoid
function4.4 whose
transition from an output close to 0 to an output close to ![]() centers
around
centers
around ![]() . Specific sigmoid functions employed by SNoW's various
learning algorithms are discussed in the next section.
. Specific sigmoid functions employed by SNoW's various
learning algorithms are discussed in the next section.
The only other testing policy currently implemented in SNoW is automatically enabled for networks which contain exactly one target node. This single-target testing policy makes predictions similarly to the classical versions of the linear threshold algorithms SNoW supports by simply returning the prediction of the single target node (either positive or negative as determined by the equation discussed above) as SNoW's prediction.
SNoW can then display for the user its prediction for each example, its accuracy across an entire labeled testing set, the activations of each target node for each example, those same activations after softmax normalization, or the results obtained from applying the sigmoid function to the activations, which will hereafter be referred to as the sigmoid activations. In simple architecture instantiations, sigmoid activations are equivalent to prediction confidences, but see Section 4.3.5 for a more in depth discussion.