The learning policy is on-line and mistake-driven (except when naive Bayes or Gradient Descent is enabled), and several update rules can be used. With the exception of naive Bayes, all update rules are variations of Winnow and Perceptron as implemented within the infinite attribute model. Below, we briefly describe the basic learning rules implemented within SNoW and point to some relevant papers. The specific ways these rules are selected and used within SNoW are described in Chapter 5.
In the default architecture instantiation, SNoW treats target nodes
independently; each is updated individually depending on its own activation
and threshold and independent of the activations of other target nodes (but
see Section 4.3.1). Target node ![]() considers a training example
positively labeled if
considers a training example
positively labeled if ![]() is active in it and negatively labeled otherwise.
In addition, if the algorithm associated with target node
is active in it and negatively labeled otherwise.
In addition, if the algorithm associated with target node ![]() is either Winnow
or Perceptron and an initial feature weight
is either Winnow
or Perceptron and an initial feature weight ![]() is not explicitly specified,
it will be calculated with the following formula:
is not explicitly specified,
it will be calculated with the following formula:
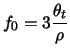
where ![]() is the threshold setting for
is the threshold setting for ![]() 's algorithm and
's algorithm and ![]() is
the average number of active features per example4.5. The justification for this formula is
purely empirical; it has been found to work well in practice.
is
the average number of active features per example4.5. The justification for this formula is
purely empirical; it has been found to work well in practice.