A Winnow update proceeds as follows:
In SNoW, Winnow's sigmoid activation is calculated with the following formula:
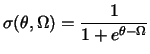
where ![]() is a target's threshold and
is a target's threshold and ![]() is a target's activation
with respect to an example.
is a target's activation
with respect to an example.
The key feature of the Winnow update rule [Littlestone, 1988] is that the number of examples required to learn a linear function grows linearly with the number of relevant features and only logarithmically with the total number of features4.6. This property seems crucial in domains in which the feature space is vast, but a relatively small number of features is relevant (this does not mean that only those will be active, or have non-zero weights). Winnow is known to learn any linear threshold function efficiently, to be robust in the presence of various kinds of noise and in cases where no linear threshold function can make perfect classification, and to still maintain its above-mentioned dependence on the number of total and relevant attributes [Littlestone, 1991,Kivinen and Warmuth, 1997].
We note that the original Winnow algorithm is a positive weight algorithm. Therefore, it is typically not expressive enough for applications. Using the ``duplication trick'' [Littlestone, 1988] is not feasible when the number of features is very large but only a small number of them is active in each example. The default SNoW architecture instantiation, using one target node for each class label (two target nodes for Boolean functions), resolves this issue. Note also that this is different from the balanced version of Winnow. This version can be run in SNoW as a special case of the true multi-class training policy (see below).