Next: Bibliography
Up: SNoW User Manual
Previous: Command-Line Parameter Index
Contents
Glossary of Terms
- activation
- See either target node activation or sigmoid
activation.
- cloud
- A collection of target nodes that all learn the concept
represented by the same target ID
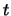 in the training set. While learning,
they maintain a cloud confidence measure that decreases whenever a mistake is
made. During testing, the sum of their sigmoid activations is weighted by
their cloud confidences, and the result is the prediction confidence that
represents in the winner-take-all competition for deciding on a
prediction. The term ``target'' (but never ``target node'') is sometimes used
as a synonym of ``cloud''.
in the training set. While learning,
they maintain a cloud confidence measure that decreases whenever a mistake is
made. During testing, the sum of their sigmoid activations is weighted by
their cloud confidences, and the result is the prediction confidence that
represents in the winner-take-all competition for deciding on a
prediction. The term ``target'' (but never ``target node'') is sometimes used
as a synonym of ``cloud''.
- cloud confidence
- A monotonically decreasing function of the number of
mistakes a learning algorithm has made with respect to a particular target
node. Cloud confidence values are in the range
![$ (0, 1]$](img133.gif) .
.
- confidence
- See either cloud confidence or prediction
confidence.
- conjunctions of features
- See option -g. SNoW learns to represent
each target node as a linear function over its active features. This may not
be expressive enough to represent the true concept. You may want to generate
more expressive features as input to SNoW, using a tool like
FexB.1 or use this option available
within SNoW. Note that this is recommended only if the number of active
features in each example is small.
- cycle
- See training cycle.
- demotion
- The update performed on a target node's weight vector when
that target node has mistakenly classified an example labeled negative as
positive is called demotion. In general this means that weights, and in turn,
the target node's activation, will be decreased.
- discarding features
- SNoW supports a mechanism for breaking the links
between target nodes and features if user-specified conditions are not met.
For example, the user may wish to sort features within a target node by weight
and keep only the top
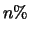 . A feature cannot be discarded until it has
become eligible. Once a feature is discarded by a target node, it can never
again become eligible within that target node during that invocation of SNoW.
See the -d option for more details.
. A feature cannot be discarded until it has
become eligible. Once a feature is discarded by a target node, it can never
again become eligible within that target node during that invocation of SNoW.
See the -d option for more details.
- eligible
- A feature status allowing that feature to contribute its
weight to activation calculations and to be included in updates. SNoW is
capable of complicated decisions regarding which features are eligible and
when they become eligible. Those decisions are made separately from the
decisions that result in discarding features. See the -e and -d
options for more details.
- feature
- The most basic unit of data processed by a machine learning
algorithm. In SNoW, features are associated with strengths in examples and
with weights in target nodes. They are combined linearly to form a
classification function.
- feature space
- The set of all possible features that may appear active
in a training example.
- feature strength
- The optional floating point value that may be
associated with a feature in an example. Feature strengths specify the
fraction of that feature's weight in a target node that should be added to the
target node's activation during both training and testing.
- full network
- By default, SNoW generates a sparse network (see
below). Option -s allows the user to override this default. The result
is a network in which all features encountered during training are linked to
all target nodes.
- incremental learning
- SNoW's terminology for training on testing
examples. Normally, a network is written to disk after training, and that
network is used but not modified during testing. The -i parameter is
used to enable network updates when mistakes are made during testing.
- learning rate
- An algorithmic parameter used by both Perceptron and
Winnow controlling the magnitude of weight updates. Perceptron uses
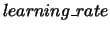 and
and
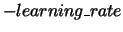 to update after mistakes on positive
and negative examples respectively. Winnow uses
to update after mistakes on positive
and negative examples respectively. Winnow uses 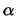 and
and 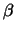 in the
same way.
in the
same way.
- link
- The dynamically allocated space in a target node's representation
which stores information about how a particular feature relates to that target
node. SNoW's learning architecture framework is based on the infinite
attribute model in which the number of features active in a training set is
potentially much smaller than the total number of features in the feature
space. Therefore, instead of maintaining a weight vector in each target node
with an index for every possible feature, links are allocated between target
node and feature when they are seen active in the same example.
- multi-class classifier
- A classification function capable of
distinguishing between two or more classes. While SNoW can still be
considered a multi-class classifier even when training its targets
independently, it is also capable of making training decisions based on
comparisons between targets. See Section 4.3.1 for more details.
- multiple labels
- See option -m. SNoW allows examples to have
multiple labels. When training a specific target , it is learned as a
function of all other features that are active with it, which may or may not
include (depending on the option -m) those features that are also targets.
- naive Bayes
- An off-line, probabilistic update rule. In SNoW, the
statistics used to calculate the conditional probabilities naive Bayes works
with are collected in an on-line fashion during training. When training is
complete, those statistics are then converted to feature weights within the
target nodes.
- network
- An instantiation of the SNoW learning architecture framework.
In addition to describing the structure of the instantiated architecture, the
network contains the hypothesis (learned features' weights), training
statistics, and algorithmic parameters. For research purposes you may find it
useful to look at the network or even post process it to learn more about the
learned hypothesis. See Chapter 6 for its structure.
- pending
- A feature status that is neither eligible nor discarded.
Pending features do not participate in activation calculations or updates and
are not written to the network file (but see the -a option for a
counter-example). Unlike discarded features, pending features can become
eligible. Depending on the eligibility mechanism chosen (see the -e
option), features may start as eligible and then become either pending or
discarded, or they may start as pending and then become eligible. A pending
feature is never directly discarded; it must become eligible first.
- Perceptron
- An on-line, mistake driven, additive update rule.
Perceptron updates the weights in a target node by adding to them a learning
rate that is a function of the type of mistake made (either positive or
negative) and the strengths of features in the example.
- policy
- See either testing policy or training policy.
- prediction confidence
- A target's prediction confidence is the sum over
all its target nodes of their sigmoid activations multiplied by their cloud
confidences. Note that when a target has been assigned a single algorithm to
learn it, its prediction confidence is equal to its target node's sigmoid
activation. Target nodes' prediction confidences are compared to determine if
a prediction will be made (see the -p option) and to decide on a
prediction in the winner-take-all testing policy.
- prediction threshold
- The smallest difference between highest and second
highest prediction confidence that SNoW will allow when deciding whether or
not to make a prediction on a testing example. See option -p for more
details.
- promotion
- The update performed on a target node's weight vector when
that target node has mistakenly classified an example labeled positive as
negative is called promotion. In general this means that weights, and in
turn, the target node's activation, will be increased.
- sparse example
- An example whose active features comprise only a small
fraction of all features in the feature space.
- sparse function
- A function that has been learned over features that
comprise only a small fraction of all features in the feature space.
- sparse network
- A network in which only those features that are active
in the same example as a target node are linked to . This is
significant for computational efficiency, size of representation, and
performance. Option -s allows the user to override this default and use
a full network.
- sequential model
- A multi-class classification model in which a subset
of targets in the network is selected to process data on a per example basis.
For example, targets
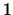 through
through 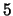 may all be represented in a given
network. Under the sequential model, a given example may request that it only
be used to update the weights in targets nodes with IDs
may all be represented in a given
network. Under the sequential model, a given example may request that it only
be used to update the weights in targets nodes with IDs 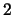 and
and 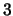 . See
Section 4.3.4 for more details.
. See
Section 4.3.4 for more details.
- sigmoid activation
- The result obtained from applying a learning
algorithm specific sigmoid function to a target node's activation, having a
range of
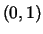 . Sigmoid activations of target nodes representing the same
target are combined to form prediction confidences.
. Sigmoid activations of target nodes representing the same
target are combined to form prediction confidences.
- single-target
- A testing policy which only operates on networks that
contain a single target node. This policy simply compares the activation of
the lone target node to the threshold of the algorithm used by that node to
make a prediction.
- smoothing
- In SNoW, smoothing is the special treatment of features in a
testing example that were never encountered during training. The naive Bayes
algorithm in particular requires weights of unseen features to be smoothed.
Specifically, if feature
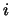 is observed in a testing example and has never
been observed with target in training, the corresponding weight
is observed in a testing example and has never
been observed with target in training, the corresponding weight 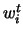 is
substituted with a fixed value. That value is then multiplied by the
feature's strength in the testing example, and the result is subtracted
from the target node's activation. See option -b.
is
substituted with a fixed value. That value is then multiplied by the
feature's strength in the testing example, and the result is subtracted
from the target node's activation. See option -b.
- strength
- See feature strength.
- target
- The representation of a class label in a network. By default,
each target learns to predict its own presence in the training examples
independently. In SNoW's most common usage, a target's representation is
simply a single target node. Clouds (see Section 4.3.5) allow a
target to be represented by multiple target nodes. When used in that sense,
the term ``target'' can be used interchangeably with the term ``cloud''. The
term ``target'' can also be used as short-hand for the target ID that appears
in an example.
- target node
- The data structure on which an update rule operates.
Target nodes keep their own set of weighted links to features. The user then
associates a (possibly different) algorithm with each target node to update
those weights.
- target node activation
- The result of the dot product of a target node's
weight vector and an example containing feature strengths. Each target node
calculates a new activation for each example. See also sigmoid
activation.
- testing policy
- An algorithm used to arrive at a prediction for an
example given the prediction confidences of all targets in the network.
Winner-take-all and single-target are the only testing policies currently
implemented in SNoW, but the various supported output modes allow the user to
take advantage of the data SNoW calculates during testing however he desires.
- threshold
- An algorithmic parameter representing the lowest activation a
target node can have with respect to a given example in order to predict that
its label in that example is positive.
- training cycle
- One pass of processing over the training examples. The
default of two training cycles can be overridden with the -r option.
- training policy
- An algorithm that decides when update rules should be
applied.
- update rule
- An algorithm, usually triggered by a mistake in prediction,
that modifies the weights in a target node based on the strengths in an
example.
- winner-take-all
- A testing policy in which the target with the highest
prediction confidence becomes SNoW's prediction for the example.
- weight
- The floating-point value associated with the link between target
node and feature. It plays the same role as weights in the weight vector of a
classical Perceptron or Winnow implementation.
- Winnow
- An on-line, mistake driven, multiplicative update rule. Winnow
updates the weights in a target node by multiplying them by a learning rate
that is a function of the type of mistake made (either positive or negative)
and the strengths of features in the example.
Footnotes
- ...
FexB.1
- Follow the Software link from: http://L2R.cs.uiuc.edu/
 cogcomp/
cogcomp/
Next: Bibliography
Up: SNoW User Manual
Previous: Command-Line Parameter Index
Contents
Cognitive Computations
2004-08-20